-
[SLASH 24]전천후 데이터 분석을 위한 DW 설계 및 운영하기Review 2025. 10. 12. 23:59
고민의 시작
- 의사 결정자가 체결된 월간 주문건수를 면밀히 사렾봐야할때나, 주문테이블, 체결 테이블, 데이터 필터링 등 복잡
- 분석을 진행하기 전에 데이터를 찾고 전처리하는 시간을 줄일 수 없을까?→ 위 과정을 미리 해둔 데이터가 있다면 좋지 않을까?
토스 증권에서 운영중인 Active User 테이블
- 특정 지표를 설정하고(act_type 이라는 명칭으로) 다양한 관점에서 측정한 테이블을 만들어내는 파이프라인을 만들어서 사용

- 위와같은 형식으로 100개가 넘는 act_type이 정의되어있음

- au_list라는 곳에 로그들을 다 밀어넣고 au_list는 daily로 존재하니 그거를 다시 montly, weekly, au_last(최종적으로 액티베이션 된 레코드 테이블), au_first(최초 인입된 레코드)로 구분하여 다시 적재
- s_au는 토스증권의 특이한 케이스라고 보면되는데 매일매일 혹은 최근 7~30일간 액티베이션 된 유니크 유저수를 집계한 테이블
- 이렇게 만들어놓으면 액트타입만 정의를 해놓으면 월간 주간 일간으로 무언가 데이터 처리를 쉽게 할 수 있다는 장점이 있음
AU테이블의 풀고자 했던 문제점
테이블과 컬럼 네이밍 컨벤션이 없어서 테이블이 일관되게 보이지 않는 문제
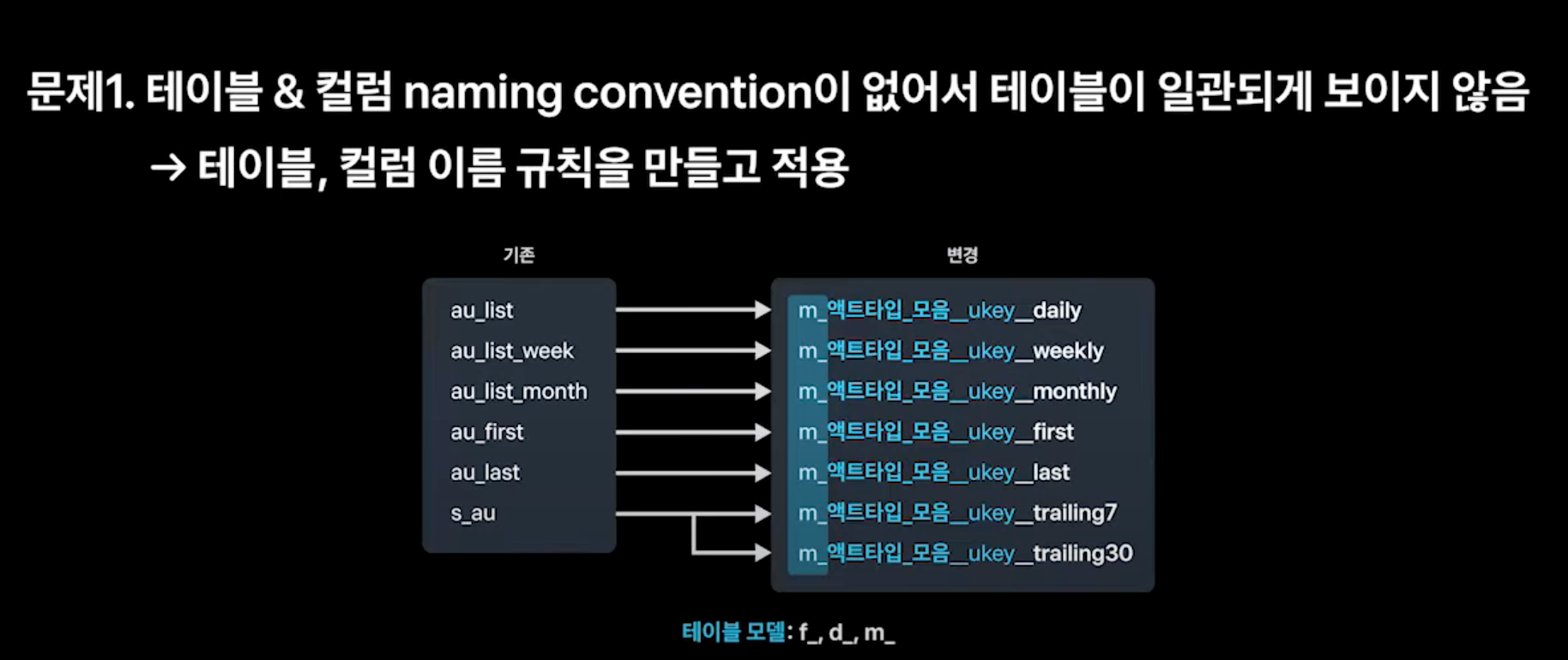
→ 여러가지 주제를 한통에 담았을때 마트성이다는 의미에 m_ 접두사를 사용함 f, d, m이라는 접두사를 통해서 네이밍 컨벤션 규칙을 만듬(f,d는 팩트앤 디멘션 모델을 차용해서 팩트 테이블, 디멘션 테이블을 의미)
- 접두사 다음으로는 액트 타입을 한통에 넣은 것이기 때문에 액트타임 모음이라는 명칭을 붙임
- 세번째 ukey는 어떤 컬럼값 기준으로 aggregation되는지를 표시
- 마지막 영역은 어떤 기한 텀으로 되어있는지 서픽스로 붙게됨
act_type별로 집계해야 하는 지표를 담아내지 못하고 모든 act_type에 적용되는 일반적인 공통의 지표만 담고있는 문제

- 각 act_type별 최초 activation된 기록이 실버 레이어로만 존재하고 사라짐→ au_list테이블에는 공통 지표값만 저장되어 확장성이 떨어짐

- 변경 이후 실버 테이블을 다 버리지않고 액트타입별로 각각의 완성된 마트테이블로 구축하고 특수하게 집계해야하는 컬럼들을 반영함
복귀, 기존유저를 집계할 수 있는 정보가 없는 문제
- 테이블을 애드훅하게 그때마다 생성해야했고 관리의 어려움이 커짐

- 유저별 activation된 기점으로 여러가지 분석 measure를 담을 dimension 정보를 추가로 생성

- 신규여부, 복귀여부 등을 쉽게 구할 수 있음

- 변경된 파이프라인 DAG
추가로 고려했던 사항
테이블 생성 로직 코드의 재활용성 높이기

- f_02_daily_table.py파일 하나로 최대한 모든 경우를 처리할 수 있도록함
- 파일 5가지로 모든 act_type을 커버할 수 있도록함
작업 병렬도를 높이기
- 테이블이 많아지면 read time이 높아져서 act_type별 spark session 설정 최적화와 불필요한 step을 줄이며 작업 병렬도를 높이는데 집중함
- airflow에 priority_weight라는 기능이 있는데 이걸 사용해서 오래걸리는 task들을 먼저 돌리도록 함
- pyspark의 executor, memory size, suffle_partitions를 커스텀하게 셋팅

- 실버 stock_visti 테이블 하나로 골드테이블 3개를 만들 수 있음
backfill을 쉽게 할 수 있는 dag 구성
- 로그데이터의 특성상 프론트에서 코드 변경시 하루 이틀정도 백필해야할 경우가 생기는데 백필 dag를 잘 구성해두지 않으면 그때마다 힘든 과정이 됨
- airflow variable을 사용해서 돌리고싶거나 제외하고자하는 act_type을 json형태로 입력해서 백필

- 특정 테이블만 돌려야하는 경우, 테이블 스펙을 적으면 해당 테이블만 백필이 되도록 구성


- 많은 기간을 선택해서 백필을 하면 메모리가 넘쳐서 터질 수 있으니 기간을 잘라서 보낼 수 있도록 구성
- 예를들어 split_date_unit에 30을 입력하면 30일만큼 task를 잘라서 생성함
최종적인 AU 테이블 사용법





- 이전에는 m로그 테이블을 뒤져가면서 봐야했지만 dw설계 이후에는 단순 select 쿼리로 가능
- 기존에는 많은 join과 계산 쿼리가 들어갔어야하지만 이후에는 간단한 sql코드로도 가능
앞으로 남은 과제
- 신규 act_type을 쉽게 추가할 수 있는 admin 화면 구축하기→ 현재 완료
- AU 테이블을 가지고 SQL LLM bot 생성하기
'Review' 카테고리의 다른 글
2025 KafkaKRU(카프카 한국 사용자 모임) 2회 밋업 참석 후기 (1) 2025.09.11 [SLASH24]토스뱅크 오픈소스로 Hadoop 클러스터 구축기 정리 (0) 2025.03.16 (if Kakao 2024)최적의 CDC 시스템 구축기 세션 정리 (0) 2025.03.02 if kakao 2024 주키퍼 없이 운영하는 카프카 운영 노하우 세션 정리 (0) 2025.02.11 네이버 DAN24 플링크와 아이스버그를 활용한 데이터 웨어하우스 세션 정리 (1) 2025.01.19